Using Data Packages in Python
This tutorial will show you how to install the Python libraries for working with Tabular Data Packages and demonstrate a very simple example of loading a Tabular Data Package from the web and pushing it directly into a local SQL database. Short examples of pushing your dataset to Google’s BigQuery and Amazon’s RedShift follow.
Setup
For this tutorial, we will need the main Python Data Package library:
https://github.com/frictionlessdata/datapackage-py
You can install it as follows:
pip install datapackage
Reading Basic Metadata
In this case, we are using an example Tabular Data Package containing the periodic table stored on GitHub (datapackage.json, data.csv). This dataset includes the atomic number, symbol, element name, atomic mass, and the metallicity of the element. Here are the first five rows:
| atomic number | symbol | name | atomic mass | metal or nonmetal? |
|---|---|---|---|---|
| 1 | H | Hydrogen | 1.00794 | nonmetal |
| 2 | He | Helium | 4.002602 | noble gas |
| 3 | Li | Lithium | 6.941 | alkali metal |
| 4 | Be | Beryllium | 9.012182 | alkaline earth metal |
| 5 | B | Boron | 10.811 | metalloid |
You can start using the library by importing datapackage. Data
Packages can be loaded either from a local path or directly from the
web.
import datapackage
url = 'https://raw.githubusercontent.com/frictionlessdata/example-data-packages/master/periodic-table/datapackage.json'
dp = datapackage.DataPackage(url)
At the most basic level, Data Packages provide a standardized format
for general metadata (for example, the dataset title, source, author,
and/or description) about your dataset. Now that you have loaded this
Data Package, you have access to this metadata using the metadata
dict attribute. Note that these fields are optional and may not be
specified for all Data Packages. For more information on which fields
are supported, see
[the full Data Package standard][spec-dp].
print(dp.descriptor['title'])
> "Periodic Table"
Reading Data
Now that you have loaded your Data Package, you can read its data. A
Data Package can contain multiple files which are accessible via the
resources attribute. The resources attribute is an array of
objects containing information (e.g. path, schema, description) about
each file in the package.
You can access the data in a given resource in the resources array
by reading the data attribute. For example, using our our Periodic
Table Data Package, we can return all elements with an atomic number
of less than 10 by doing the following:
print([e['name'] for e in dp.resources[0].data if int(e['atomic number']) < 10])
> ['Hydrogen', 'Helium', 'Lithium', 'Beryllium', 'Boron', 'Carbon', 'Nitrogen', 'Oxygen', 'Fluorine']
If you don't want to load all data in memory at once, you can lazily
access the data using the iter() method on the resource:
rows = dp.resources[0].iter()
rows.next()
> {'metal or nonmetal?': 'nonmetal', 'symbol': 'H', 'name': 'Hydrogen', 'atomic mass': '1.00794', 'atomic number': '1'}
rows.next()
> {'metal or nonmetal?': 'noble gas', 'symbol': 'He', 'name': 'Helium', 'atomic mass': '4.002602', 'atomic number': '2'}
rows.next()
> {'metal or nonmetal?': 'alkali metal', 'symbol': 'Li', 'name': 'Lithium', 'atomic mass': '6.941', 'atomic number': '3'}
Loading into an SQL database
Tabular Data Packages contains schema information about its
data using JSON Table Schema. This means you can easily import
your Data Package into the SQL backend of your choice. In this case,
we are creating an SQLite database in a new file
named datapackage.db.
To load the data into SQL we will need the JSON Table Schema SQL Storage library:
https://github.com/frictionlessdata/jsontableschema-sql-py
You can install it by doing:
pip install jsontableschema-sql
Now you can load your data as follows:
# create the database connection (using SQLAlchemy)
from sqlalchemy import create_engine
engine = create_engine('sqlite:///periodic-table-datapackage.db')
# now push the data to the database
from datapackage import push_datapackage
push_datapackage(descriptor=url,backend='sql',engine=engine)
If you have sqlite3 installed, you can inspect and play with your
newly created database. Note that column type information has been
translated from the JSON Table Schema format to native SQLite types:
$ sqlite3 periodic-table-datapackage.db
SQLite version 3.8.10.2 2015-05-20 18:17:19
Enter ".help" for usage hints.
sqlite> .schema
CREATE TABLE ___data___data (
"atomic number" INTEGER,
symbol TEXT,
name TEXT,
"atomic mass" FLOAT,
"metal or nonmetal?" TEXT
);
Loading into BigQuery
Loading into BigQuery requires some setup on Google's infrastructure, but once that is completed, loading data can be just as frictionless. Here are the steps to follow:
- Create a new project - link
- Create a new service account key - link
- Download credentials as JSON and save as
.credentials.json - Create dataset for your project - link (e.g. "dataset")
To load the data into BigQuery using Python, we will need the JSON Table Schema BigQuery Storage library:
https://github.com/frictionlessdata/jsontableschema-bigquery-py
You can install it as follows:
pip install jsontableschema-bigquery
The code snippet below should be enough to push your dataset into the cloud!
import io
import os
import json
from apiclient.discovery import build
from oauth2client.client import GoogleCredentials
from jsontableschema_bigquery import Storage
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '.credentials.json'
credentials = GoogleCredentials.get_application_default()
service = build('bigquery', 'v2', credentials=credentials)
project = json.load(io.open('.credentials.json', encoding='utf-8'))['project_id']
push_datapackage(descriptor=url,backend='bigquery',project=project,service=service,
dataset='dataset')
If everything is in place, you should now be able to inspect your dataset on BigQuery.
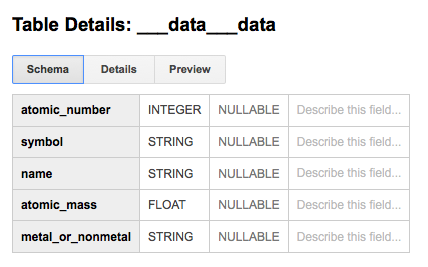
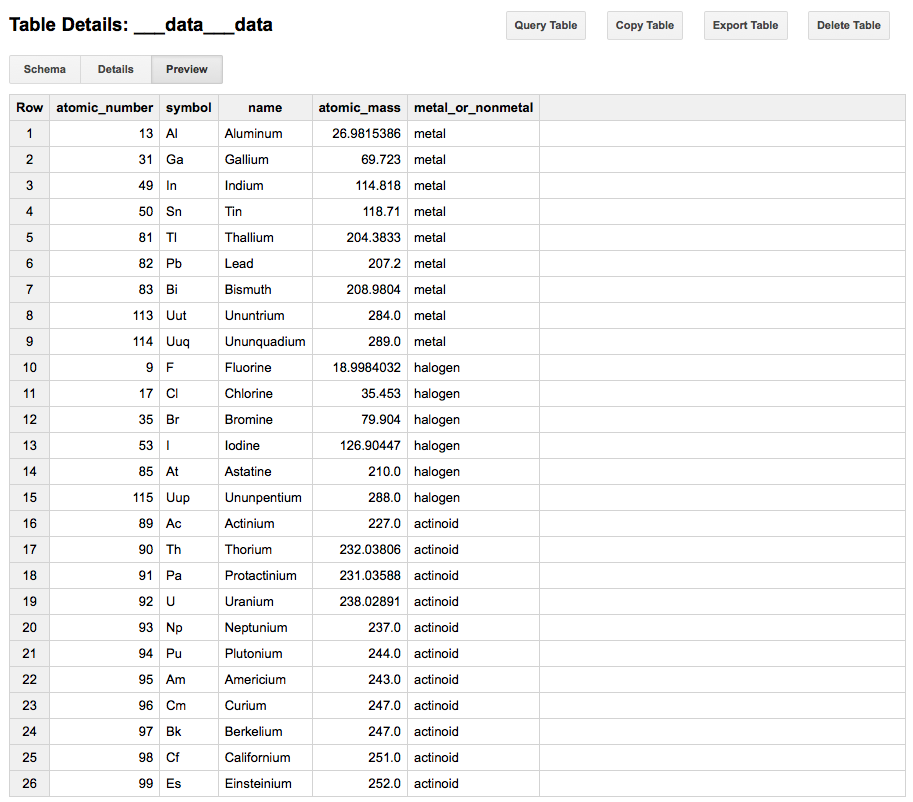
Loading into Amazon RedShift
Similar to Google's BigQuery, Amazon RedShift requires some setup on AWS. Once you've created your cluster, however, all you need to do is use your cluster endpoint to create a connection string for SQLAlchemy.
Note: using the sqlalchemy-redshift dialect
is optional as the postgres:// dialect is sufficient to load your
table into AWS RedShift.
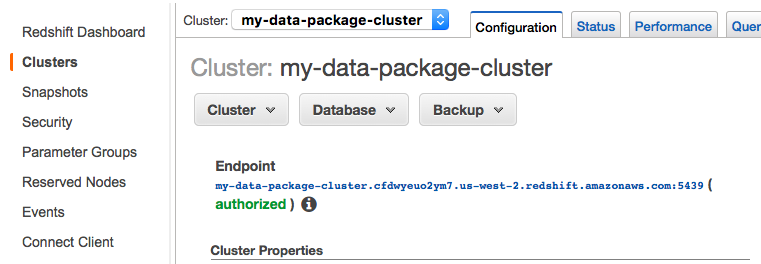
# create the database connection (using SQLAlchemy)
REDSHIFT_URL = 'postgres://<user>:<pass>@<host>.redshift.amazonaws.com:5439/<database>'
from sqlalchemy import create_engine
engine = create_engine(REDSHIFT_URL)
# now push the data to the database
from datapackage import push_datapackage
push_datapackage(descriptor=url,backend='sql',engine=engine)