Our Vision
Frictionless Data is about removing the friction in working with data. We are doing this by developing a set of tools, specifications, and best practices for publishing data. The heart of Frictionless Data is the Data Package specification, a containerization format for any kind of data based on existing practices for publishing open-source software.
Read more / less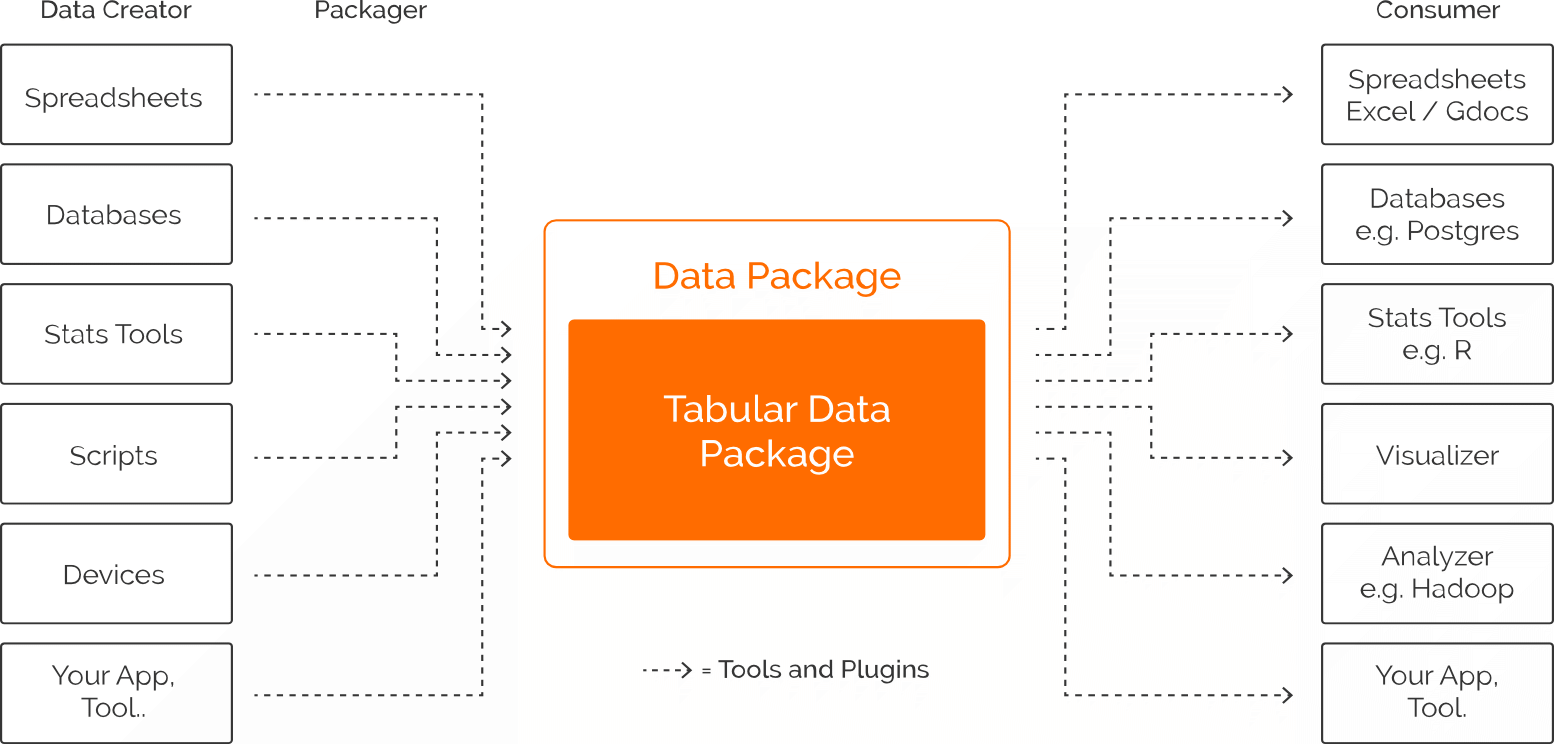
Informed by our work building and deploying CKAN and learning about various data publication workflows, we have learned that there is too much friction in working with data. The frictions we seek to remove---in getting, sharing, and validating data---stop people from truly benefiting from the wealth of data being opened up every day. This kills the cycle of find/improve/share that makes for a dynamic and productive data ecosystem.
We provide a simple wrapper and basic structure for transportation of data that significantly reduces the friction in data sharing and integration, supports automation and does this without imposing major changes on the underlying data being packaged. We focus on tabular data but any kind of data can be "packaged". Its lightweight and simple nature it is easy to adopt both for data publishers, data users and data tool makers.
We have been working on these and similar issues for nearly a decade, and we think that the time is right for frictionless data. Help us get there.
Data "Containerization"
We see our approach as analogous to standardization efforts in the transport of physical goods. Historically, loading goods on a cargo ship was slow, manual, and expensive. The solution to these issues came in the form of containerization, the development of several ISO specifications specifying the dimensions of containers used in global shipping. Containerization dramatically reduced the cost and time required for transporting goods by enabling the automation of several elements of the transport pipeline.
We currently consider transporting data between and among tools to be comparable to shipping physical goods in the pre-containerization era. Currently, before you can properly begin an analysis of your data or build a data-intensive app, you have to extract, clean, and prepare your data: procedures that are often slow, manual, and expensive. Radical improvements in data logistics---through specialisation and standardisation---can get us to world where we spend less time sorting through and cleaning data and more time creating useful insight.
Principles
1. Focused: Focus on one part of the data chain, one specific feature (e.g. packaging), and a few specific types of data (e.g. tabular).
2. Web-oriented: Build for the web using formats that work naturally with HTTP such as JSON, a common data exchange format for web APIs, and CSV, which is easily streamable.
3. Distributed: Design for a distributed ecosystem with no centralized, single point of failure or dependence.
4. Open: Make things that anyone can freely and openly use and reuse with a community that is open to everyone.
5. Built Around Existing Tooling: Integrate with existing tools while also designing for direct use---for example, when a Tabular Data Package integration is unavailable, fall back to CSV.
6. Simple: Keep the formats and metadata simple and lightweight, and make things easy to learn and use by doing the least required.